
##Kaggle
The Kaggle competition for Machine Learning “Digit Recognizer” is like a “hello world” for learning machine learning techniques.
In this competition, a small subset of MINST digit of handwritten gray scale images is given.
Any machine-learning algorithm could be used to classify the test set based on the classification model determined by the training set. In this post, we discuss about how the KNN algorithm could be used to label these digits. A python script is used to run this algorithm on the test and training sets. No inbuilt machine learning python packages are used in the program for learning purposes.
##KNN KNN is a lazy learning algorithm, used to label a single test sample of data based on similar known labeled examples of data. The algorithm finds the “K” most nearest training examples and classifies the test sample based on that. The following image from Wikipedia gives a visual example of how the KNN works.

If K=3, the unknown green dot would be classified as a “Red Triangle” based on the “3 nearest neighbors” If K=5, the unknown green dot would be classified as a “Blue Square” based on the “5 nearest neighbors”. So, how are the “nearest neighbors” determined? We use the Euclidean distance formula:
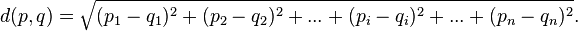
This determines the distance between two values in a N-dimensional plane.
##Handwritten Digits – MINST data set
A small subset of MINST data of handwritten gray scale images is used as test dataset and training dataset. They contain several thousand 28×28 pixel gray scale images that look like this:
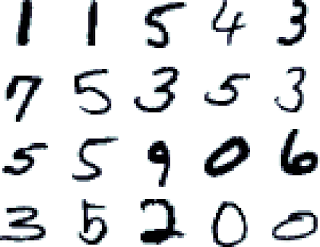
Each of the images is given in the format of 784 comma-separated pixel values in gray scale. The training data has the first value as the labeled value of the image.
So, how do we determine the Euclidean distance between two such images? We do that by determining the difference between each of corresponding pixels of the images and squaring them. So, if the two images were exactly the same, then the squared distance would be 0. For images, which are similar, we would expect this distance to be as small as possible.
##Implementation using Python:
A digit class is defined with possibility to initialize with label and pixel array data. A distance function is defied to determine the Euclidean distance between two digits, by calculating the difference in pixel values between the digits.
1
2
3
4
5
6
7
8
9
10
class Digit:
def __init__(self):
self.label=''
self.data=[]
def distance(self,digit):
sum=0
for i in range(0,len(self.data)):
sum=sum+(self.data[i]-digit.data[i])**2
return sum**.5
The training set is processed from the “train.csv“ file as follows. For every row in the data set, a new Digit class is defined. The first column is marked as the label, and the pixel data is appended to the Digit’s pixel array. The digit is then appended to an array and returned. The first row is ignored as it has the column labels and not the actual data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def get_training_set():
dataset=[]
with open('../data/train.csv','rb') as csvfile:
csvreader=csv.reader(csvfile)
rownumber=0
for row in csvreader:
if not rownumber==0:
data=Digit()
dataset.append(data)
colnumber=0
for col in row:
pixels=[]
if colnumber==0:
data.label=col
else:
data.data.append(int(col))
colnumber=colnumber+1
rownumber=rownumber+1
return dataset
The test set is processed from the “test.csv” file similar to the training set and stored in a test dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
def get_test_set():
dataset=[]
with open('../data/test.csv','rb') as csvfile:
csvreader=csv.reader(csvfile)
rownumber=0
for row in csvreader:
if not rownumber==0:
data=Digit()
dataset.append(data)
for col in row:
data.data.append(int(col))
rownumber=rownumber+1
return dataset
Once the Training and the test datasets are processed, the next step is to compare the test set against the “K” nearest neighbors in the training set. For every test set of data, we loop through the training set of data; we find the distance of the test digit image from each image in the training image based on the Euclidean formula. We sort the results by distance (We want to find the closet digits).
After this we find the first “K” results and we aggregate them based on labels. In the example below K = 10, i.e., we use the nearest 10 neighbors to classify the test digit. After aggregation, we sort the labelmap in the descending order to pick the top-most common neighbor and “label” the test digit as that value. For example; if the labelmap of a test digit looks like this: [(‘2’, 7), (‘0’, 2), (‘6’, 1)], we label the digit as 2, as those are the nearest neighbors.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
trainingset=get_training_set()
testset=get_test_set()
f=open('./out.csv','w')
f.write('ImageId,Label\n')
i=1
for test in testset:
results=[]
for train in trainingset:
distance=test.distance(train)
touple=distance,train
results.append(touple)
results=sorted(results,key=lambda result:result[0])
labelmap={}
for y in range(0,10):
result=results[y]
l=result[1].label
if l in labelmap:
labelmap[l]+=1
else:
labelmap[l]=1
labelmap=sorted(labelmap.iteritems(),key=operator.itemgetter(1),reverse=True)
f.write(str(i))
f.write(',')
f.write(labelmap[0][0])
f.write('\n')
print i
print labelmap
i=i+1
f.close()
The above program runs quite slow as it uses the native arrays and lists of the python language. This program can be fine-tuned using numpy package for python. However, the concepts remain the same.
So how do we decide which “K” value to use? We could do this using a “cross-validation set”. The idea is to use a cross-validation to test different values of “K” and use the best value for the test set. This step was not implemented and I used some trial values of “K” ranging from 3 to 100 to determine that K = 10 gave me a fairly good accuracy.
This program gave me a prediction accuracy of 96%. So, there it is, a very simple implementation of KNN for digit recognition using python.
Fork the code at Github